Property Price Prediction
23 June 2024

Description
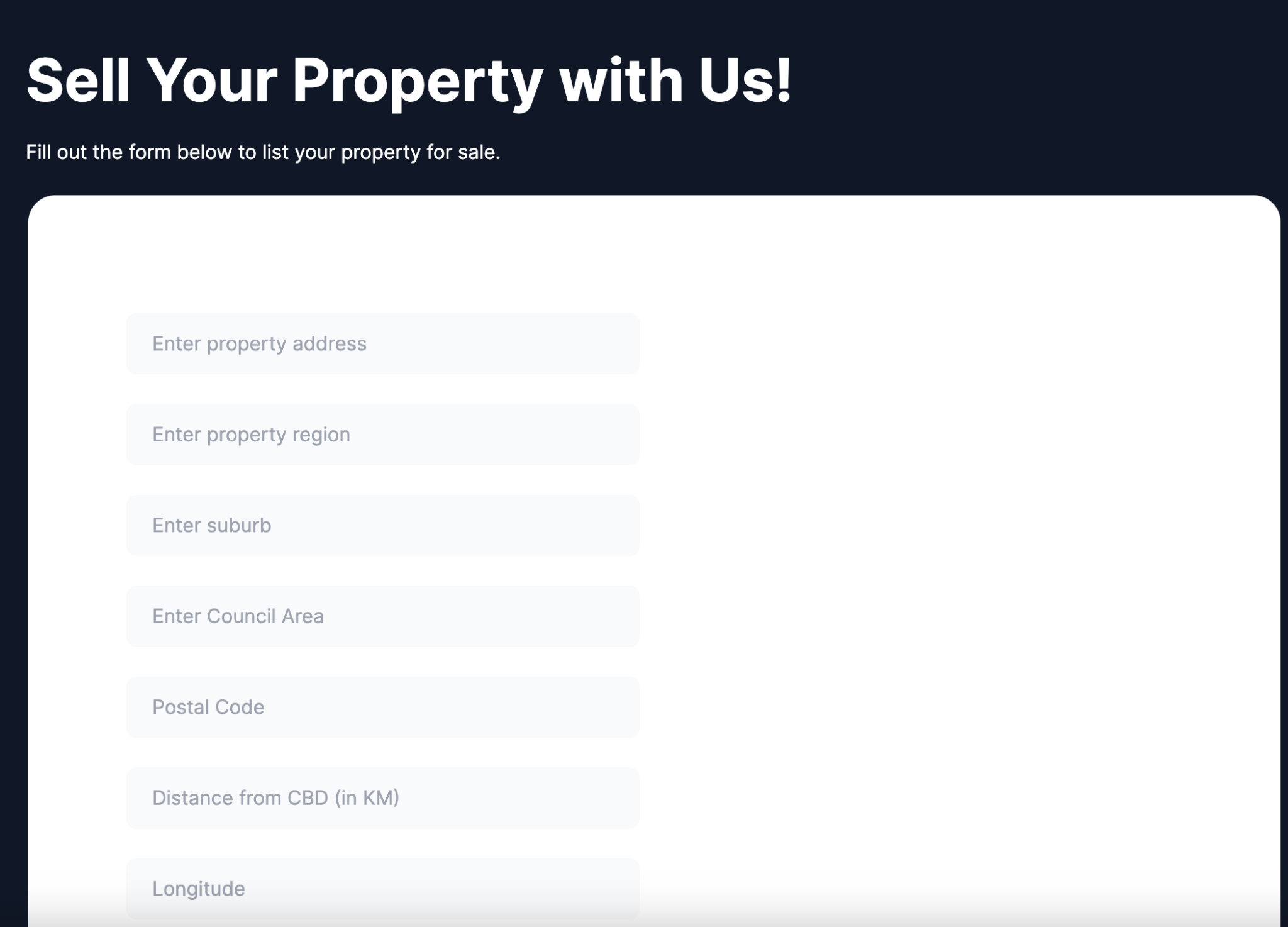
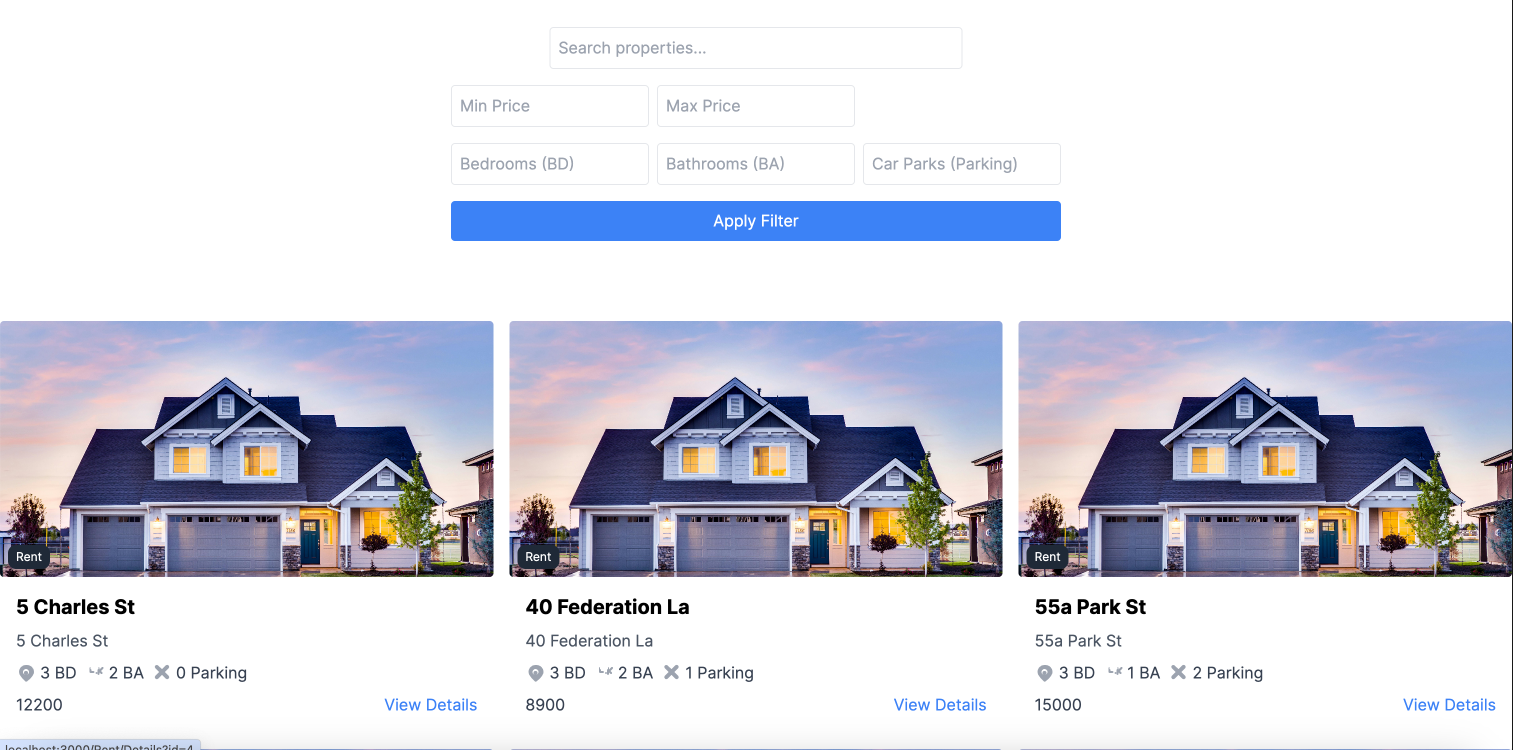
This project is a property selling/rent web app, accomplished in year 1 trimester 3 of my university period, that allows users to list properties that they want to sell or rent with the help of machine learning AI predicting prices.
Features
- Database Management (MySQL)
- Data Cleaning
- Machine Learning (ML)
Reflection
Language Used: Python
Software/Tools Used: Django, Pandas, sklearn, MySQL
Role: Data Sourcing and Cleaning, ML Model Implementation, Model Testing
Introduction
This project was developed as part of a project for our Database Management module in year 1 of university.
Our project aims to provide home buyers and renters an idea of the market price for their type of properties before making a decision. As such, we have developed a web app that utilizes machine learning algorithms to predict the price of properties based on the different attributes selected.
My role in the project was thus data sourcing, cleaning and ML model implementation.
Data Sourcing
The dataset that was used in this project was the “Melbourne Housing Snapshot” from Kaggle
The data includes Melbourne’s real estate scenario, listing a variety of statistics for each home, including “Suburb, Type, No. of rooms,” among other things. The initial downloaded dataset contained 21 columns(fields).
Data Cleaning & Processing
To meet the requirements of our program, additional data are manually generated, such as user information and rent costs. Additionally, fields like “Method” have been changed to meet the requirements of our application.
Fields like “Method” have been changed to meet the requirements of our application.
To add on, there were columns in the downloaded dataset that the team believed ought to be divided into a different dataset. For instance, there was a column called “SellerG” in the downloaded dataset. The team believed that a property should be moved to another dataset called “Listing” rather than having a seller.
Lastly, in order to produce a more comprehensive and reliable dataset, entries that were missing data from certain columns also had their information manually produced.
Database Management
For managing our data, we utilised Azure MySQL database to store and retrieve our data within our backend Django server. Django also has an ORM and Django Models to ensure consistency between the database and the backend server, hence making our development easier and human-error resistant.
Machine Learning
Machine Learning - Features
For the Machine Learning aspect, the following categorical features were used to train the model.
| Suburb | Region | |||||
| Council Area | Property Type | |||||
| Distance from CBD | No. bathrooms | |||||
| No. of Car Park slots | Longitude | |||||
| Latitude | Year Built | |||||
| Land Size | Postal Code | |||||
| Property Count | No. of Bedroom |
The categorical features are one-hot encoded into numerical values before normalizing all features’ values. The target feature of the model is the “Price” column of the dataset in which after the model’s training, results in a prediction score of 0.8 (rounded).
The features were then normalised based on their minimum and maximum ranges to a value of between 0 and 1 to ensure that all features have all the same scale. Although it is not entirely necessary to minmax-normalise these features, it is important to do so for the model used is the XGBRegressor model, tuned with the hyperparameters learning_rate and max_depth.
Machine Learning - Model
The model used was the XGBRegressor model from the sklearn library with fine tuned hyperparameters to predict prices. The hyperparameters are:
n_estimators: This determines how many trees will be build in the model with the idea to capture the complex relationship between the features like Number of Bedrooms, Land Size, Distance from CBD with the price.
learning_rate: To control how much each tree contributes to the final model. It is wise to put this a lower value to make sure the model is trained slower but with more care to ensure better generalization of data.
max_depth: This governs the depth of each tree. Deeper trees mean more complexity captured for features like Year Built, Land Size, and Property Type but having the depth set too high would also sometimes lead to wastes.
reg_lambda (L2 regularization): Regularization encourages the model to focus on the most important features (like Land Size, Distance from CBD, or No. of Bedrooms) and not overemphasize noise or irrelevant patterns (like the Postal Code or Longitude).
Tuning these hyperparameters at high values could lead to overfitting. Hence it is best if a balance could be struck to achieve the best results.
Machine Learning - Training & Testing
The dataset is split into two subsets to accomodate the training & testing phases.
Machine Learning - Results

Seeing that the Best Score = 0.807 is generally quite good for many real-world regression problems
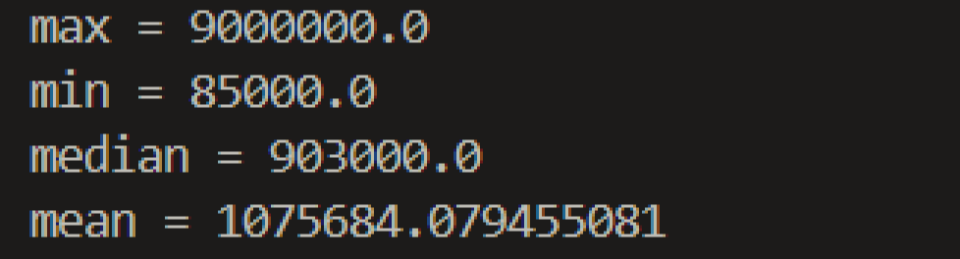
Seeing that the median of property prices is $903,000, having the Mean Absolute Error ≈ 162090.27 is relatively good.
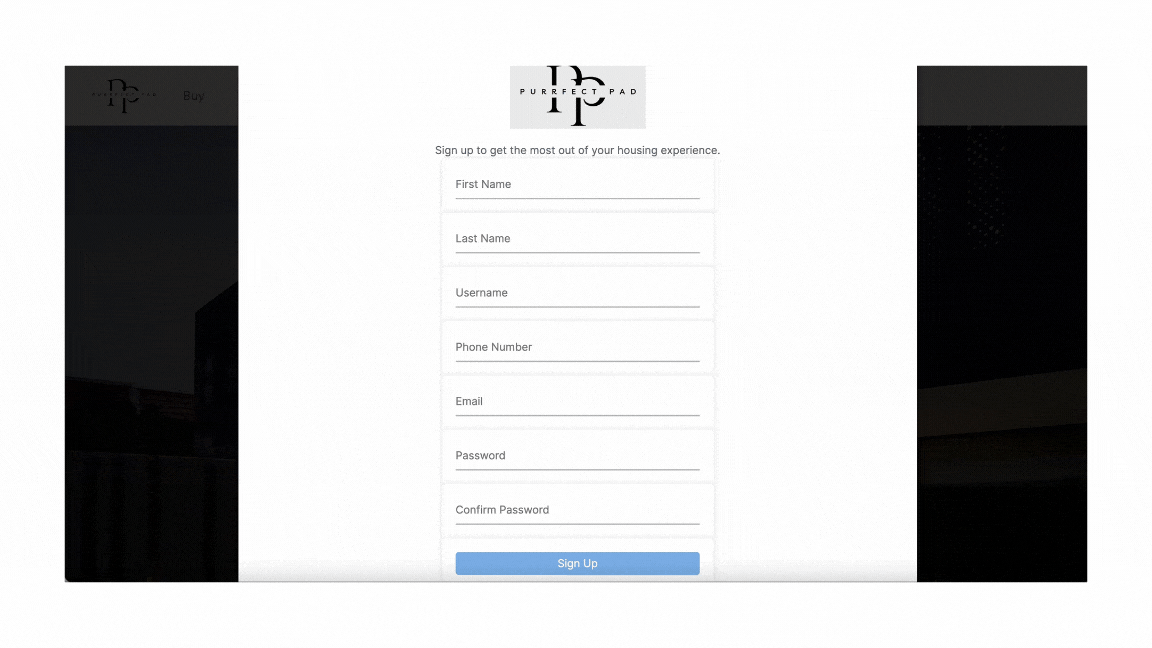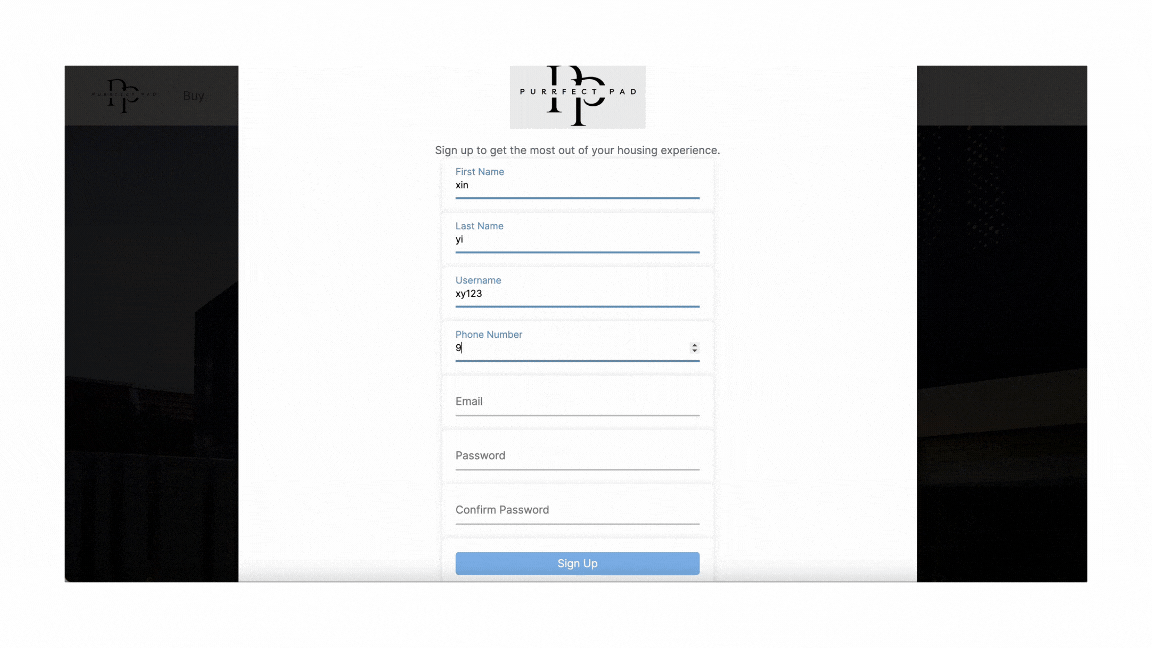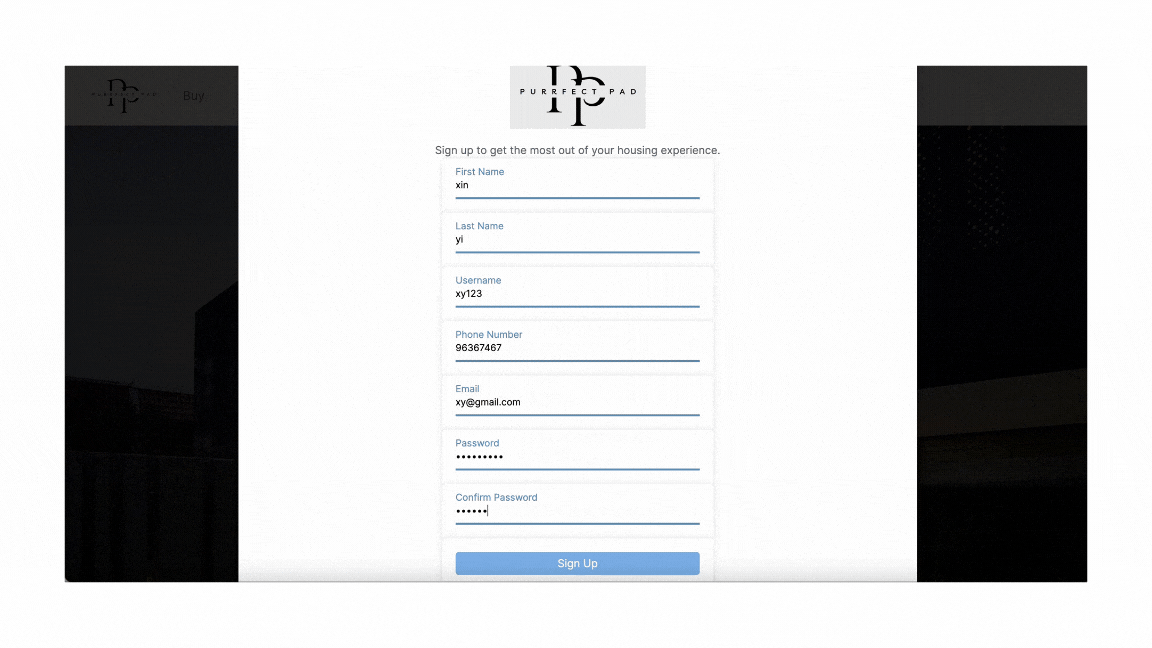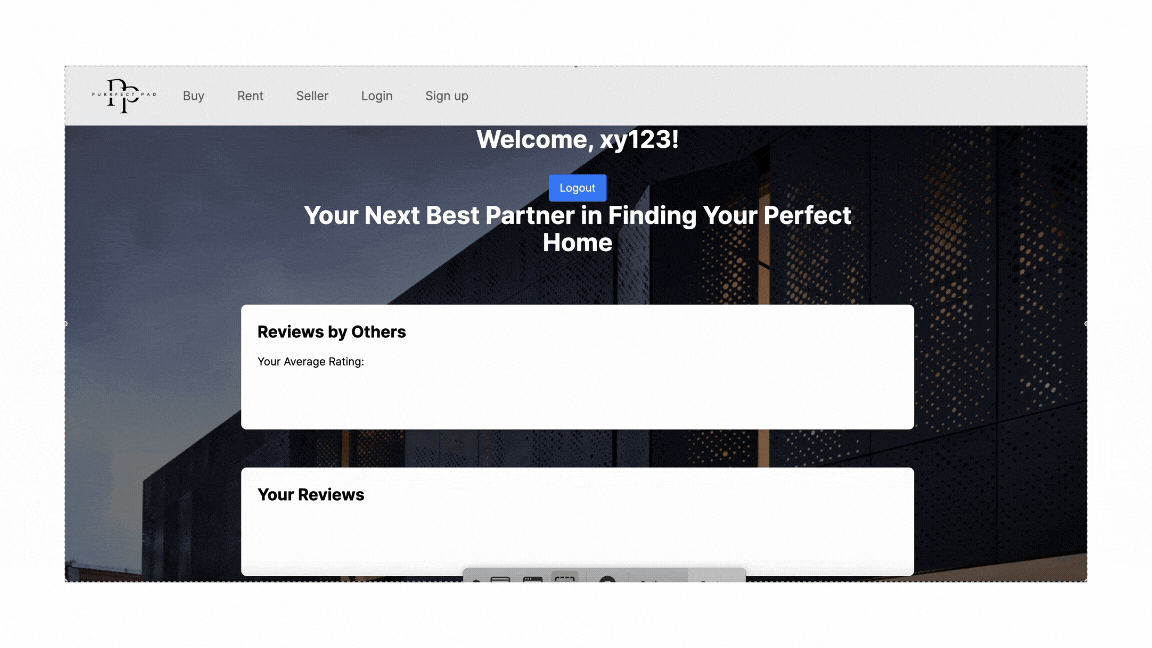
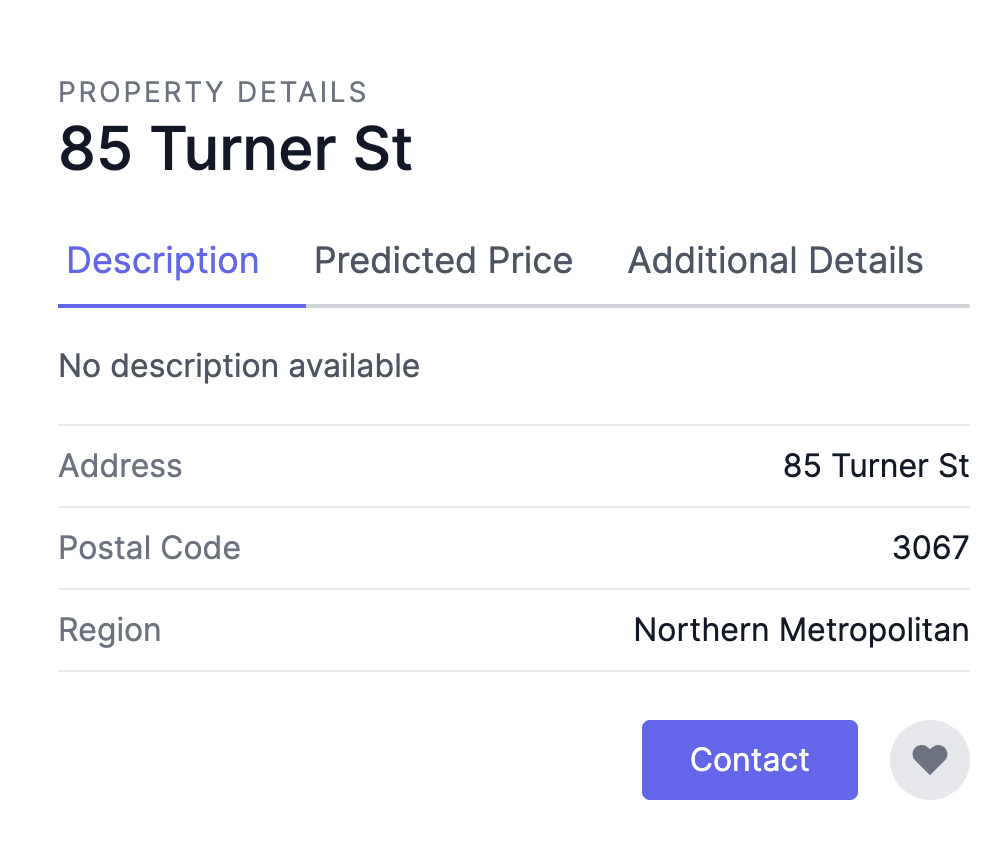
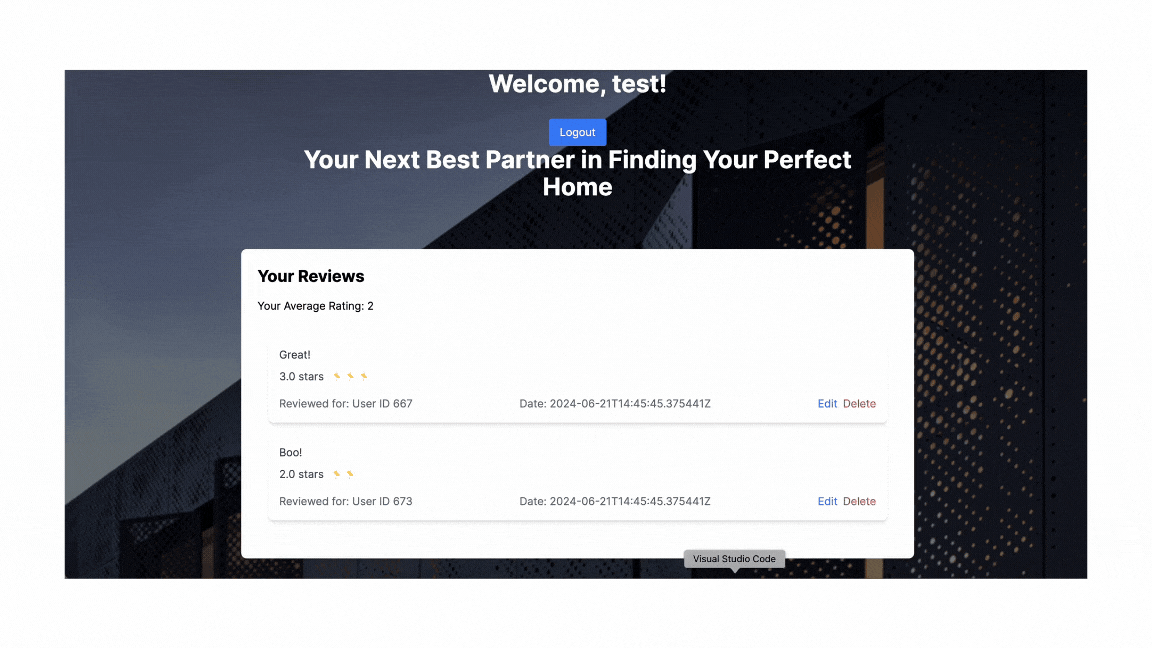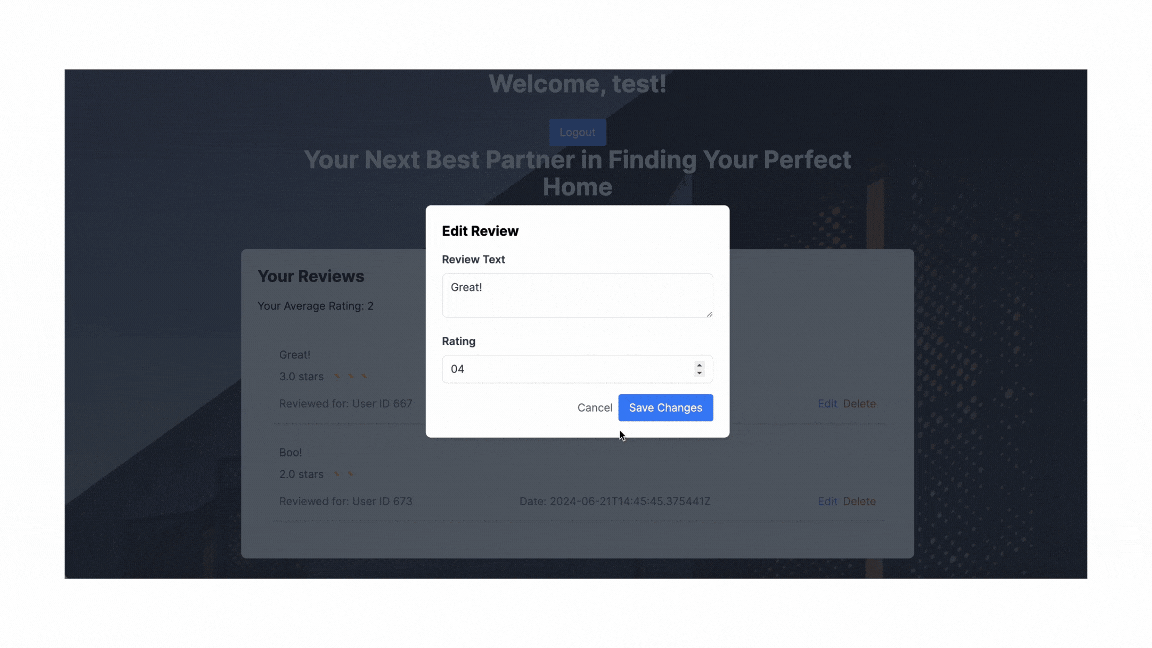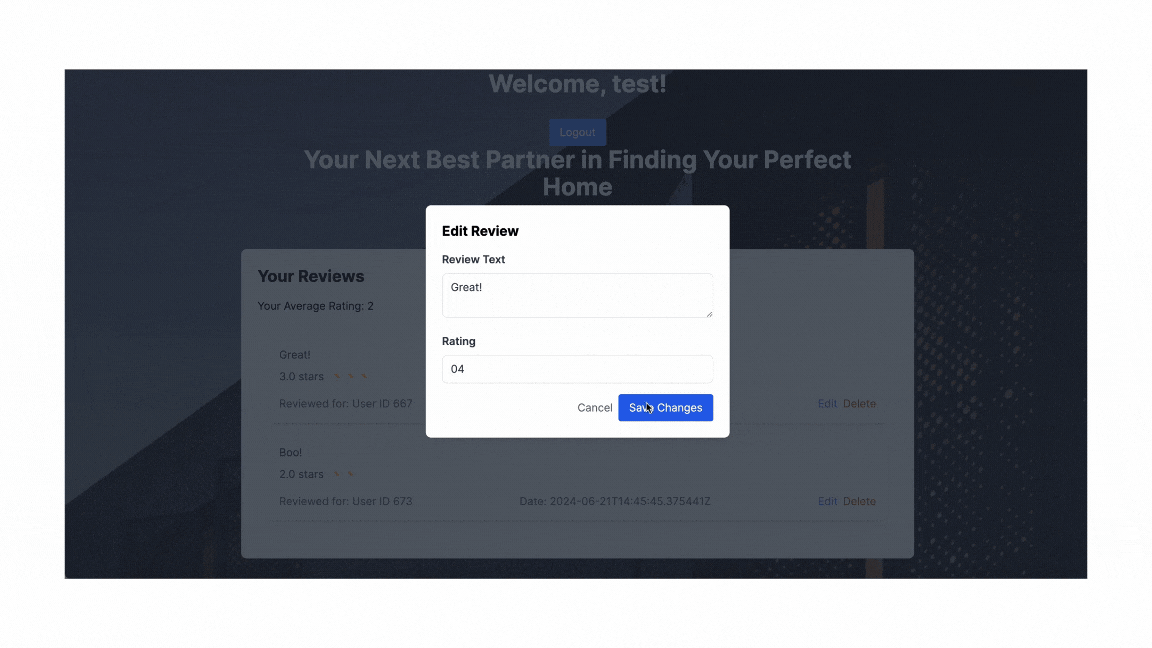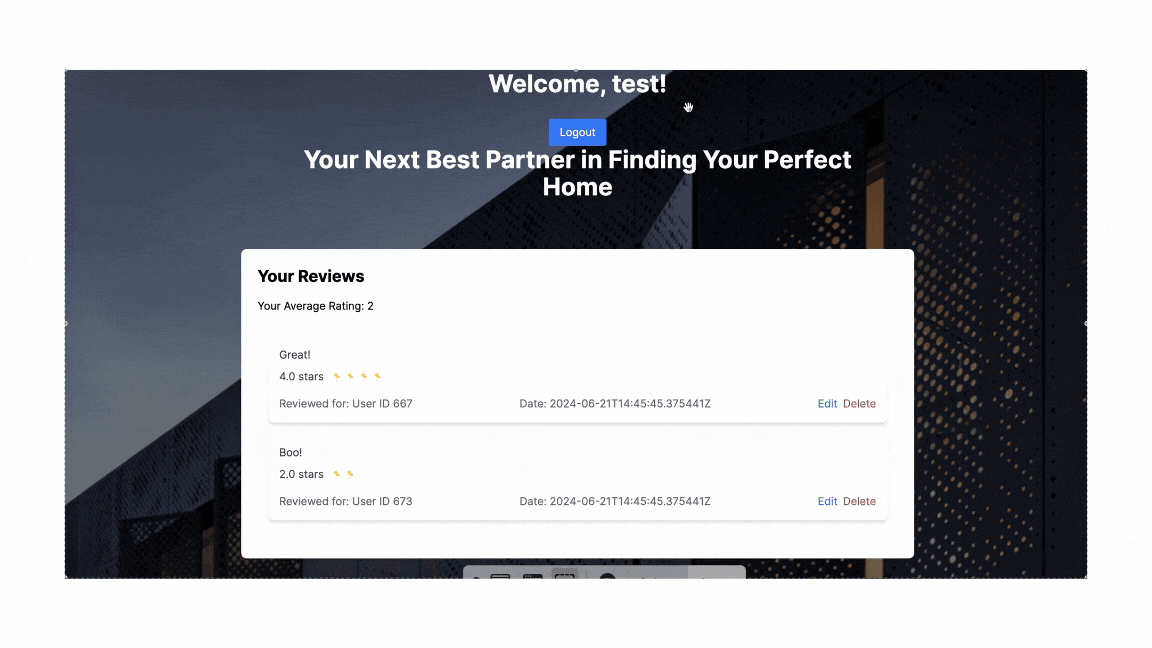
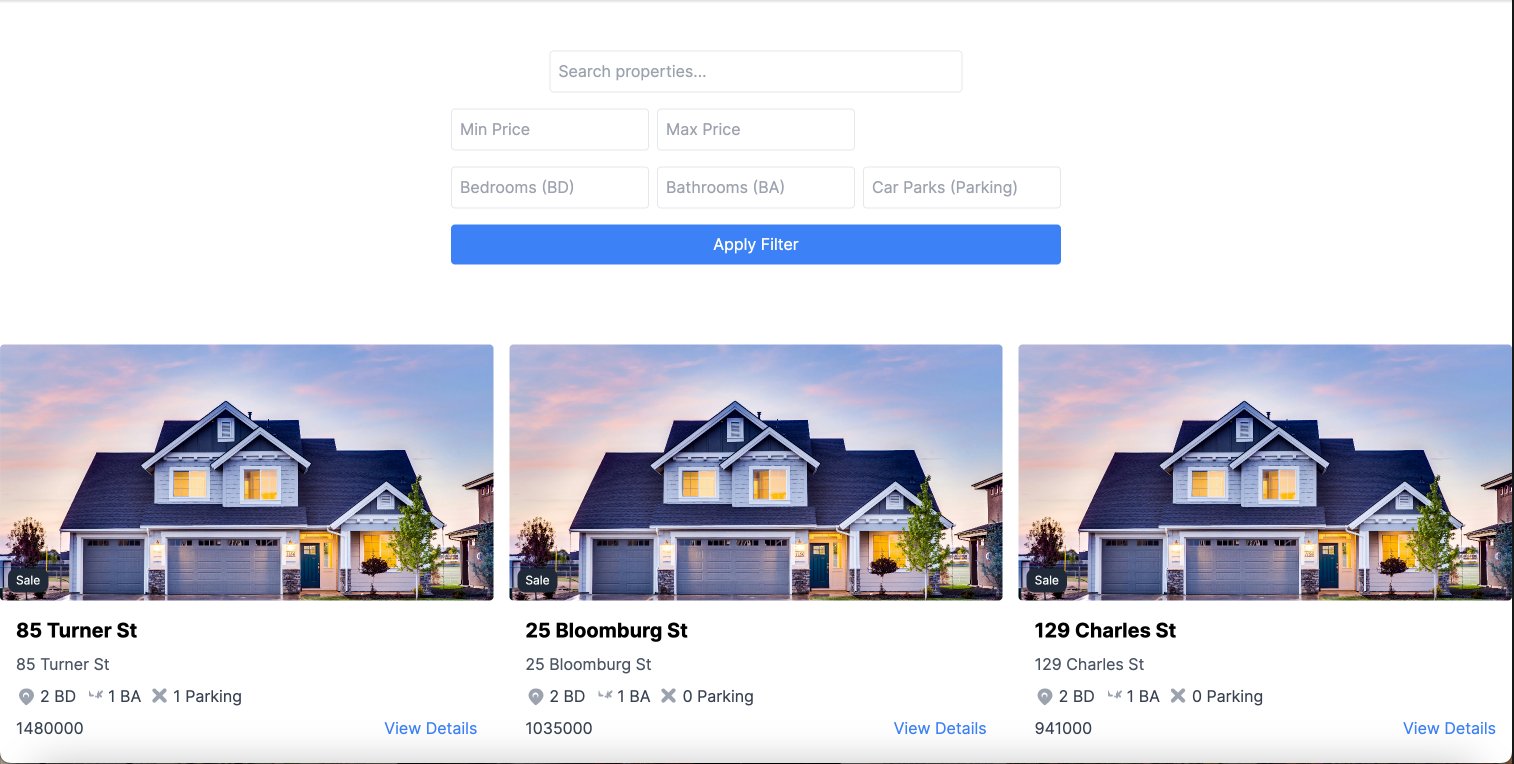
Prediction On Frontend
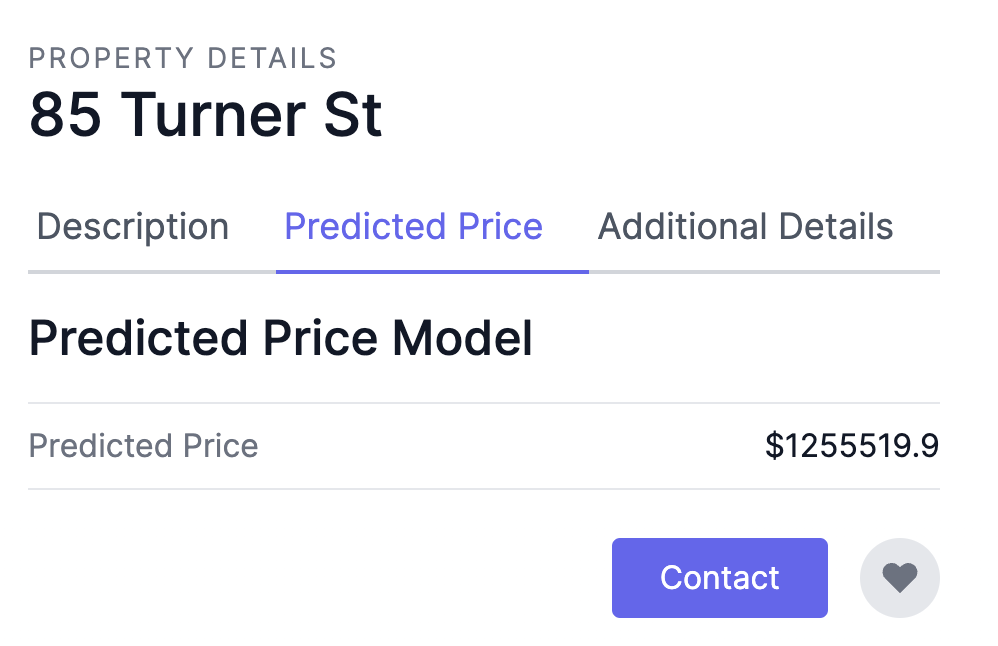
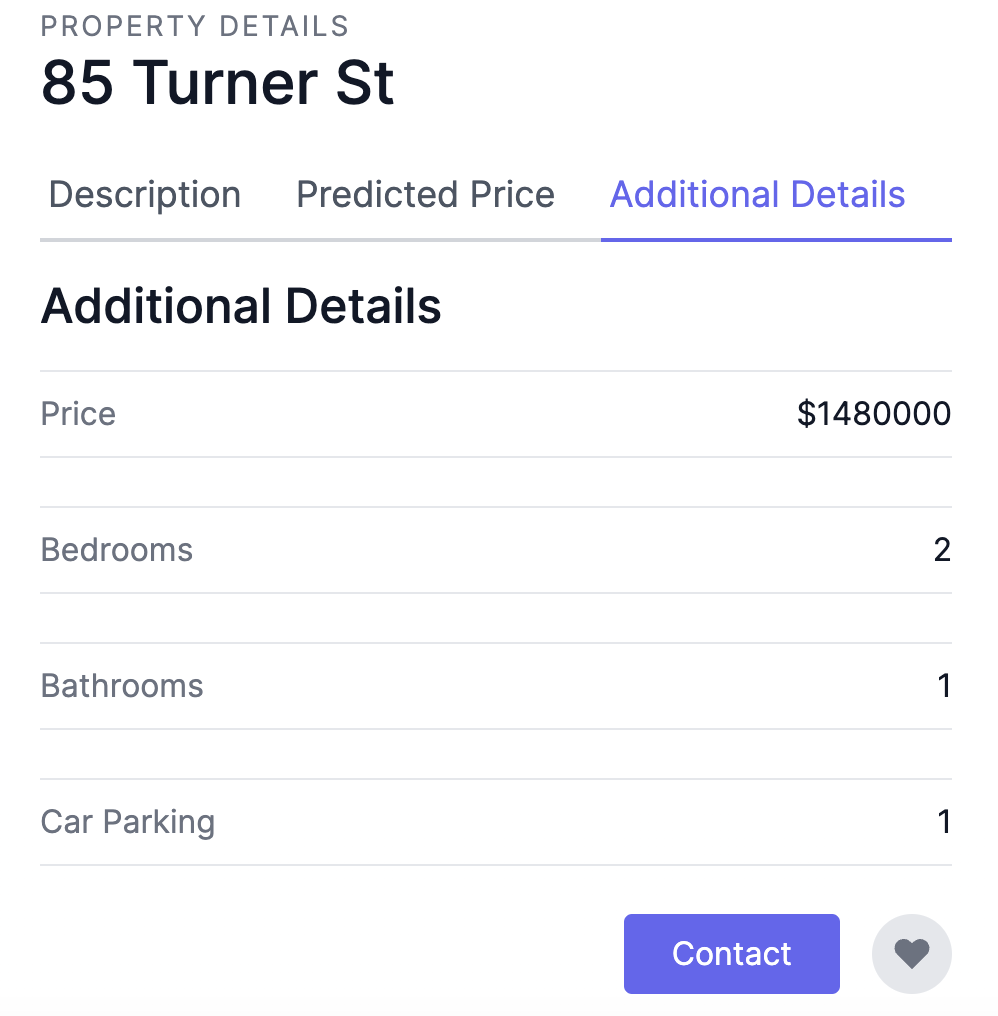
As such, this is the end result of how the property price would be viewed by the users based on the details of the property.
Images