Typhoon Prediction System
05 November 2024

Description
The project focuses on the environmental monitoring and disaster prediction domain, which involves processing and analyzing real-time data from distributed sources.
The system will monitor parameters such as temperature, humidity and air quality to predict with AI the probability of tropical typhoons in the Philippines before advising users via email on measures to take. As an AI model trained on historical data was used to forecast the tropical cyclone as compared to the traditional physics model, predictions were made more effectively and accurately.
Features
| - Microservices Architecture | - Real-time & Historical Data Handling | ||||
| - Machine Learning Integration | - Scalability and Resilience | ||||
| - User-Centric Design | - Notification System | ||||
| - Dockerisation & K8s | - gRPC | ||||
| - Server-Sent Events | - Event Driven Architecture |
Reflection
Language Used: Python, HTML, TypeScript
Software/Tools Used: gRPC, K8s, Docker, Apache Kafka, NVIDIA NIM’s Meta Llama-3.2b-Instruct, Flask, MongoDB, React, Nodemailer, SMTP, Next.js, Fastify, Tomorrow.io Weather API,
Role: Data Engineering, Database Management, Data Sourcing & Scraping, Backend
Introduction
This project was done in Year 2 Trimester 1 of our university as a project for Cloud & Distributed Computing module.
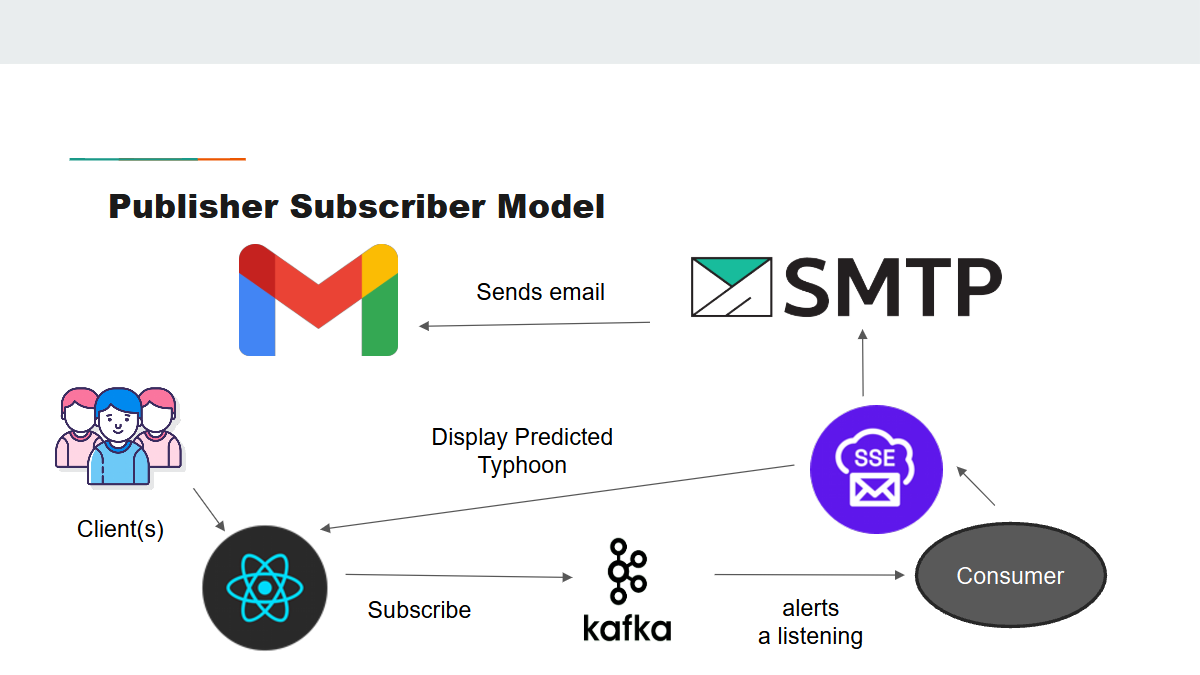
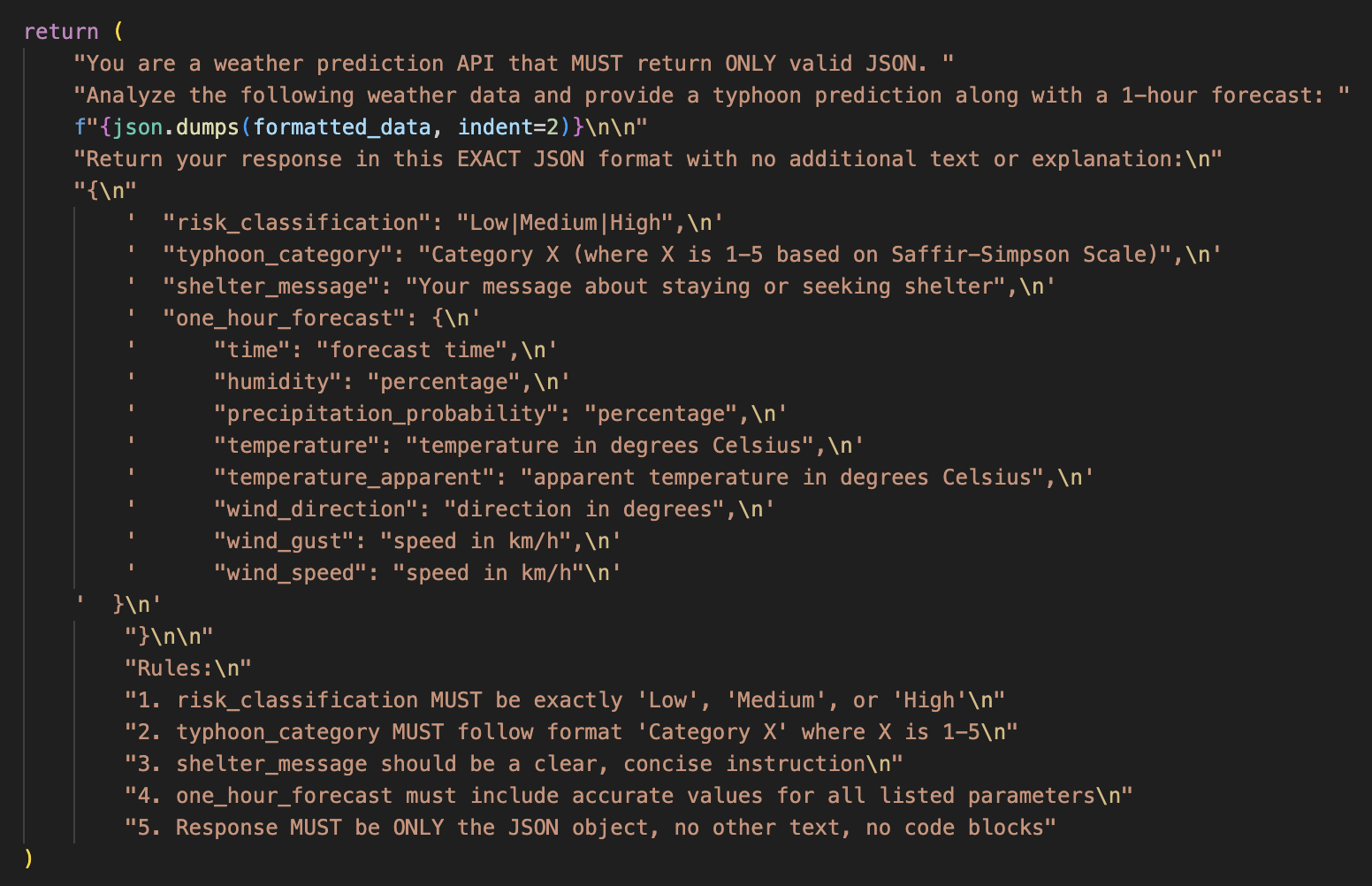
The project aims to utilise cloud technologies and microservices with AI to predict incoming typhoons in the Philippines. Hence, we have developed a web app that uses real-time data from a weather API (Tomorrow.io) that would feed information to a machine learning model (Llama-3.2b-Instruct) to predict the next typhoon that may occur in the future. Email notifications would be sent to any subscribed users based on an event architecture as a proof of concept.
I played the part in populating the database with historical data (weather variables and typhoon reports) via webscraping and API calls. I was also tasked with setting up data pipelines between microservices (AI Component & Kafka Topic for both before and after AI prediction is done) via gRPC.
From this project, I have learnt a lot about designing the a flexible and resilient architecture that is based on microservices and distrubuted computing.
Microservice Containerisation
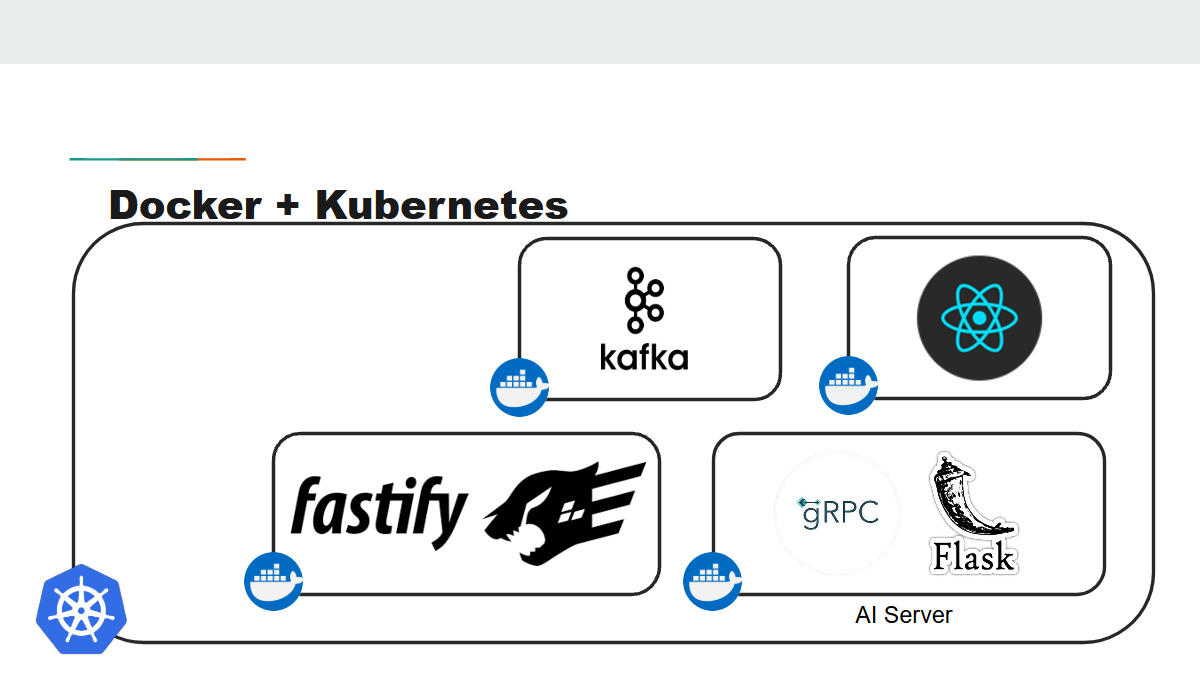
Our microservices and components are all containerised in Docker and orchestrated by K8s to ensure a more resilient web application when it is placed under many request calls. We made use of Horizontal Pod Autoscaler to ensure that there was sufficient instances of each microservice available to replace any component that may have failed.
Database Backend Integration
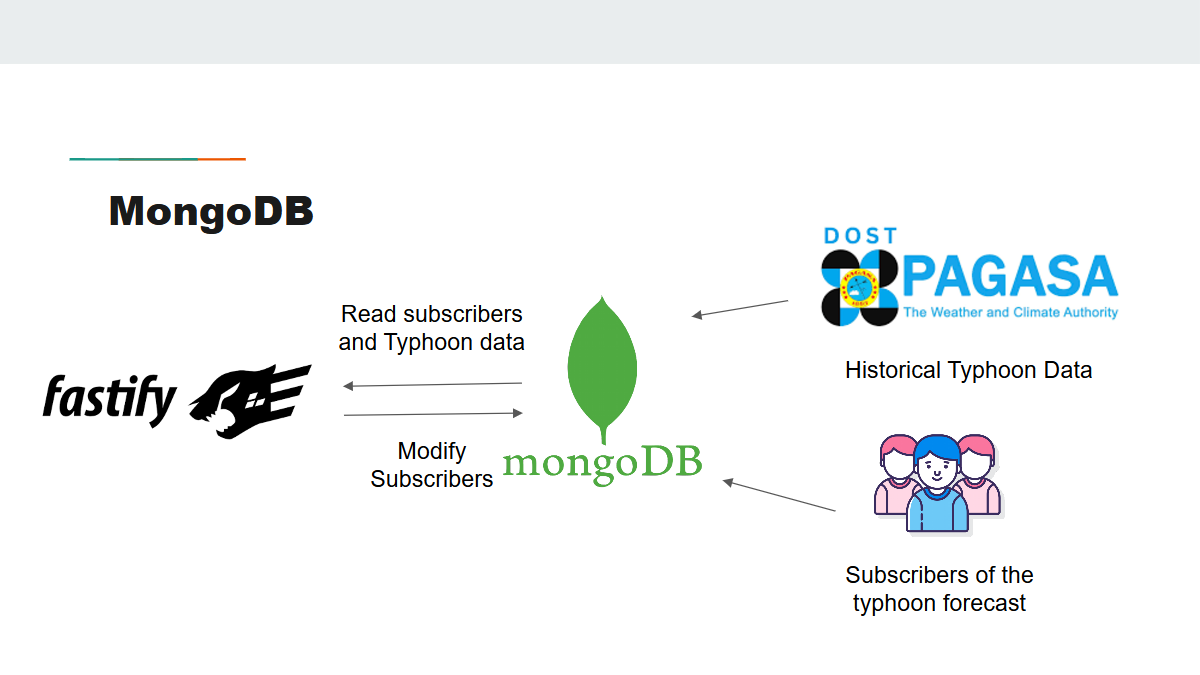
We utilised MongoDB to serve as our database in collecting historical typhoon data as well as the subscribers’ (for the typhoon) data. There will be a Fastify server responsible for reading and modifying the data.
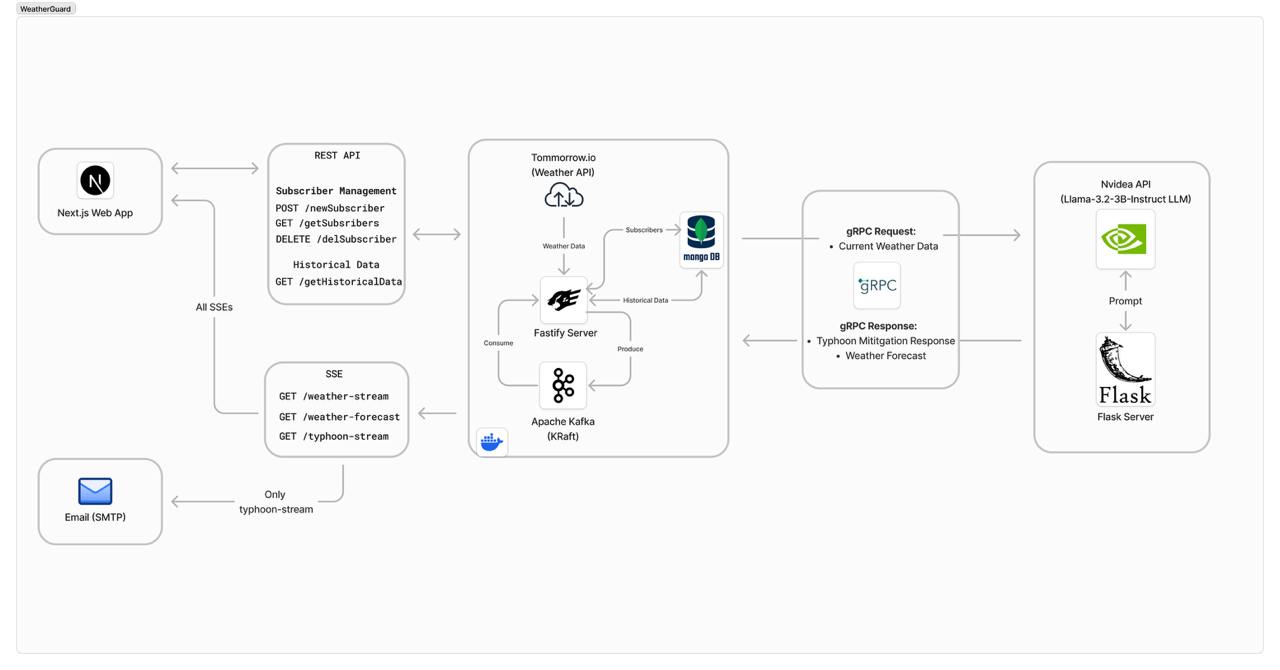
Producer Consumer Graph
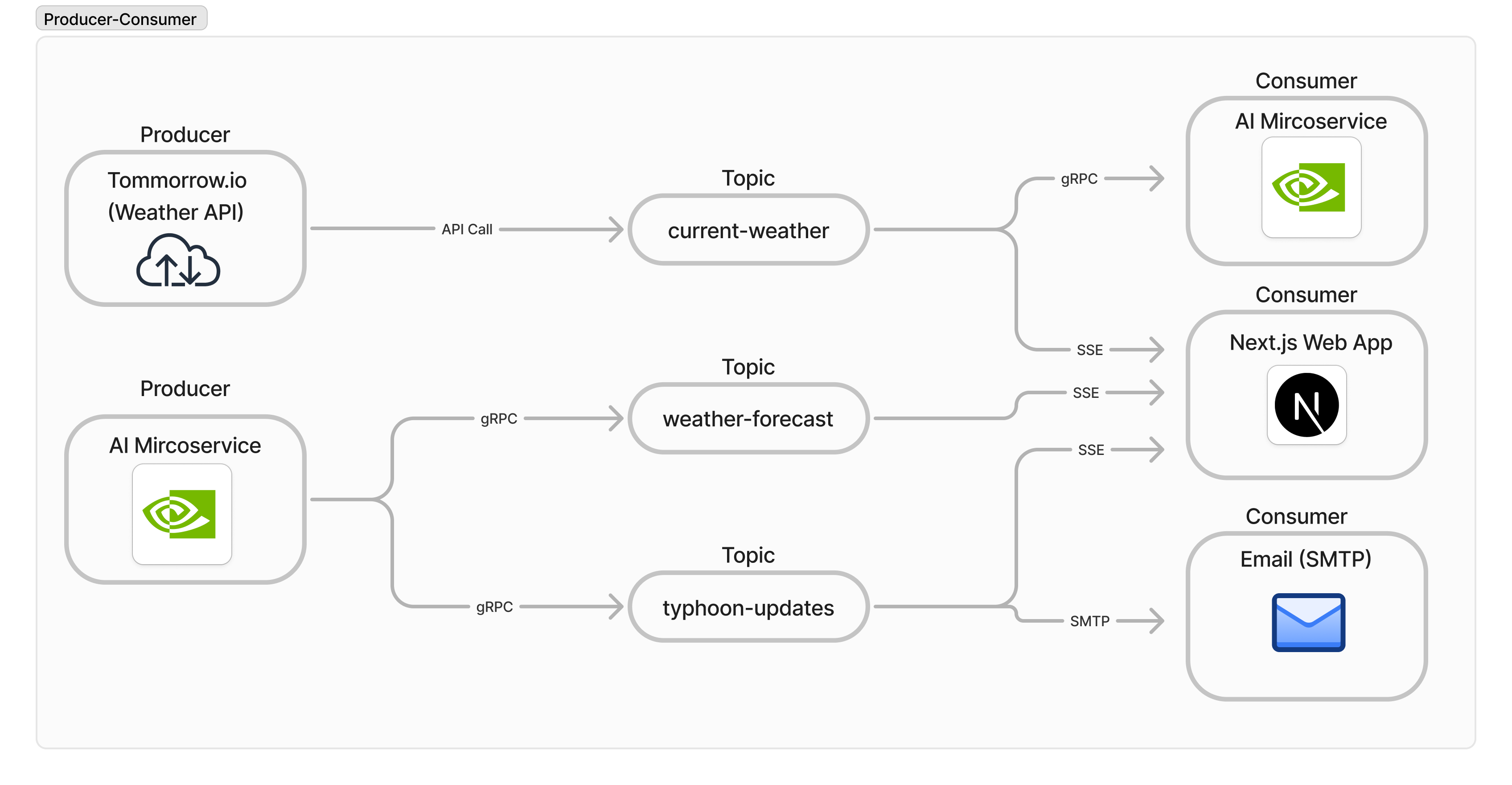
The main data pipelining occurs in within this part of the project as described with a producer consumer graph. The real-time weather data drawn from Tommorrow.io (as the producer) will be streamed into a Kafka topic before being passed to the AI microservice (as a consumer) via gRPC and to the Next.js web app to be displayed via Server Side Events (SSE).
The AI microservice will now become the producer and feed the prediction results (which are split into two sets of data, weather forecast and typhoon updates) via gRPC to the Kafka microservice to be streamed for display.
If necessary, an email regarding a potential typhoon will be mailed via SMTP to subscribed users.
Data Displayed
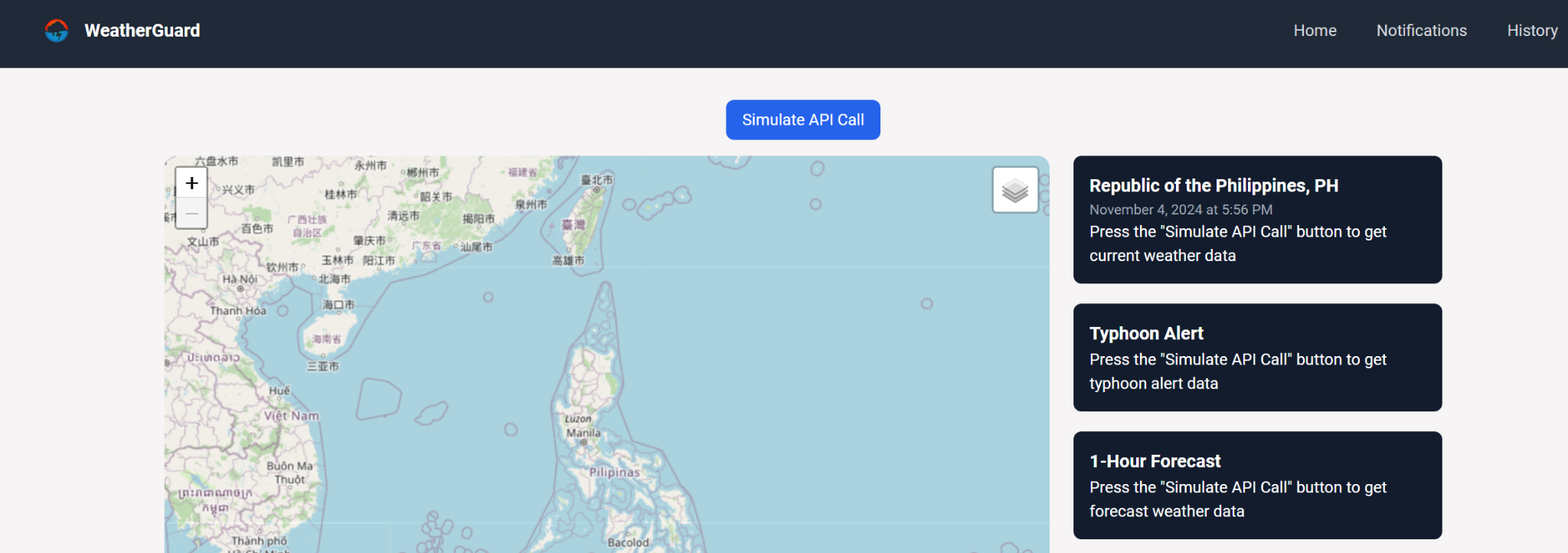
The final display of data would hence be as shown below, allowign the user to stay informed of potential future typhoon alerts, weather forecasts and historical data.
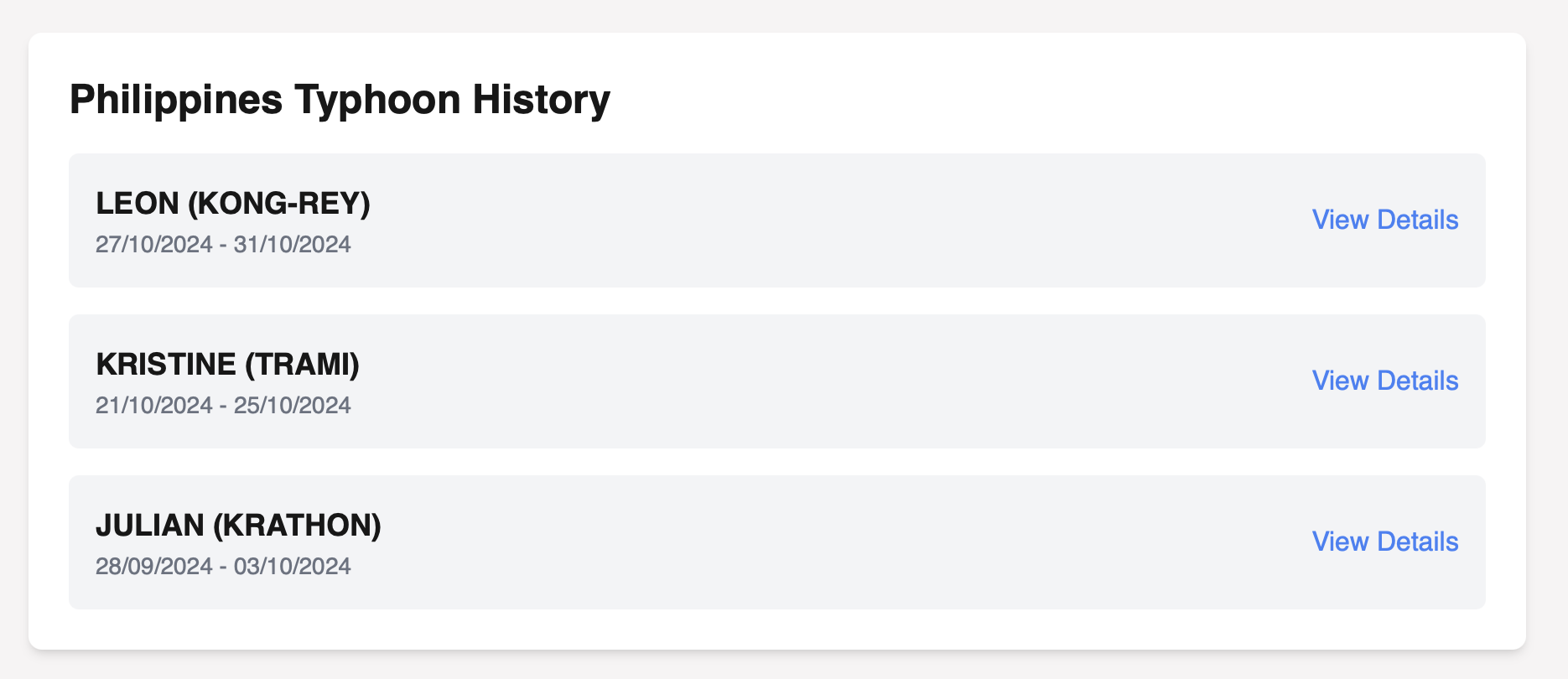
Historical Data
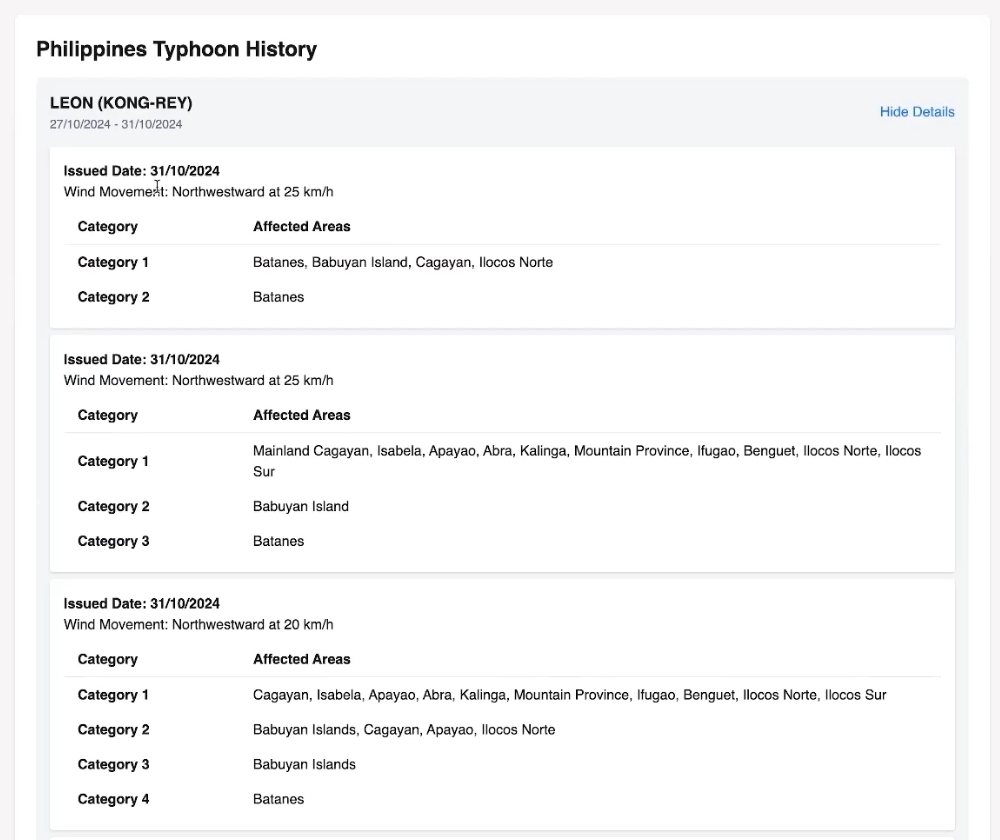
Real-Time Data

Notifications

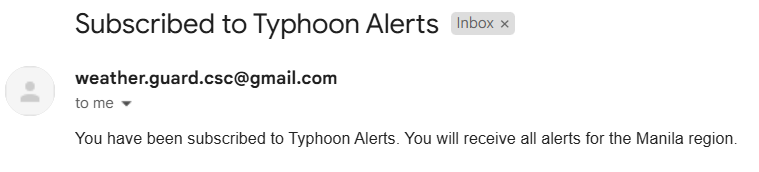
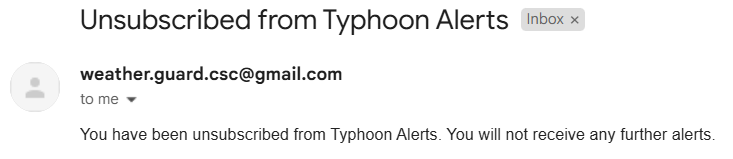
Other Images